GDLlama 1.0 Postmortem
October 19, 2025
GDLlama is a GDExtension that allows a Godot developer to use the powerful llama.cpp library to run GGUF models in Godot games.
This is a continuation of a prototype project I started a year or two ago concerning agents in video games. I was getting the emergent gameplay I wanted, but I ran into a few issues. Primarily, it was costly. I was directly calling OpenAI's APIs for every agent action, which quickly added up and wouldn't be feasible for a full game. I wanted to explore local LLM inference, but the models were too large to run on my hardware. Further, there were no Godot integrations available at the time and I didn't have the confidence to build them then; I don't even think Llama existed! So, the project had to wait.
Then, on August 14th, Google released Gemma3-270m, a tiny 270 million parameter model that ran well on most consumer hardware. There were other SLMs kicking around, but Gemma 3 270m was exciting because it fit three specific needs: 1) it was small, 2) it could follow instructions well, and 3) it provided dialogue at a level that was approaching GPT-3 quality. Game changing.
However, I quickly found that existing solutions for Godot were out of date, difficult to use, or both. So, I wanted to take a crack at it. GDLlama lets developers add AI-powered features to their games. You could do something with dialogue generation, or radiant quest creation. Have your NPCs respond dynamically to player actions, or create a DM for a virtual gaming experience that would have been impossible just a few years ago. The nascent space is just so vast and exciting, and I am so happy to contribute to it.
This was originally a fork of godot-llm by Adriankhl; I wanted to update their work to the latest version of llama.cpp so that I could use the new Gemma 3 270m GGUF in my projects, and I figured others might find it useful too. When I started working on the update, I found that there were quite a few issues with the original codebase that made it difficult to work with, so I ended up rewriting large portions of it. After a few months of development (I think I started in the end of July 2025), I tagged a stable 1.0.0 release.
The process of developing GDLlama went, admittedly, smoother than I expected. I had no experience with GDExtensions, only university experience with C++, and I was nervous to look at one codebase someone else had written. Let alone three of them! After a bit of fumbling around, resolving linting errors one at a time, then build errors, then Godot integration issues, until I was able to get a sort-of working version of the original project running with the latest llama.cpp. At that point, I realized a few things: one, not all of the access methods were working and I had no idea why; two, some of the features godot-llm implemented were no longer supported by llama.cpp or were implemented in a different way; and three, the code was a bit of a mess. Not knowing much about llama.cpp or Godot, I decided to start with the tertiary goal first: clean up the code. That was something I knew I could do, and I knew it would lead to resolving the others as well.
The Project
Refactoring + Initial Assessment
To start, I needed to figure out what GDLlama wanted to be. At that point, there were four key pieces of access:
gdllama: for LLM inferencegdllava: for vision modelsgdembeddings: for embedding modelsllm_db: an SQLite database for managing model metadata and state
and three corresponding runners:
llama_runnerllava_runnerembedding_runner
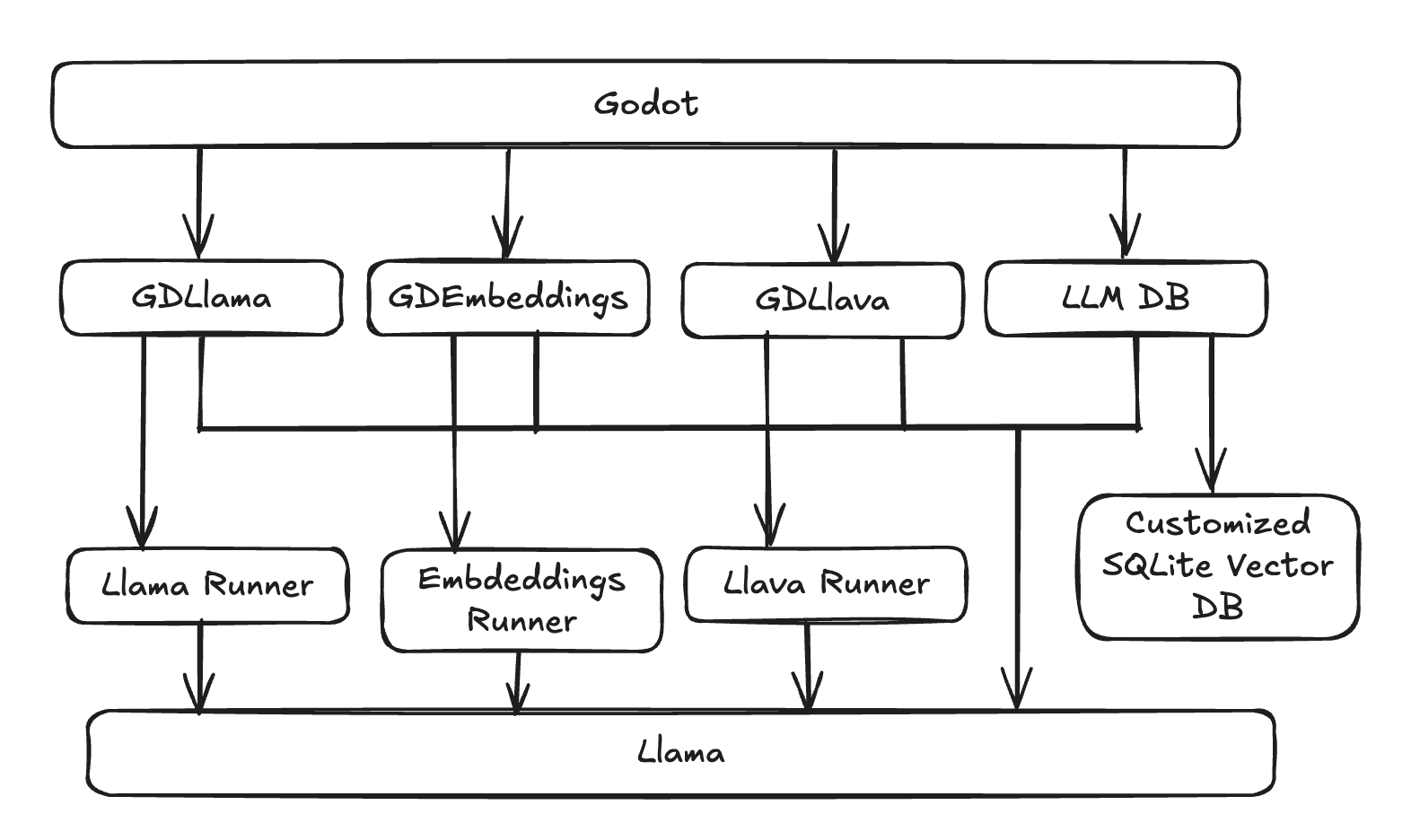
These components were quite leaky about their responsibilities. gdllama, gdllava, and gdembeddings all interfaced with llama.cpp directly, handled model loading and unloading, and managed inference calls to their corresponding runners. The runners themselves were monolithic with quite a lot of duplicated code between the three. It felt like a piece that could benefit from some consolidation.
On top of this, I found that godot-llm was loading and unloading a model with every inference call, which was not ideal.
I decided to focus on where responsibilities lay and how to simplify the codebase, which I eventually did in a PR titled "Simplify Generation". This change built the foundation for user access, and represented a significant refactor of the core feature: inference. It also represented a shift in how I wanted GDLlama to be used. No longer would there be four seperate nodes for each type of use case; instead, we would have a single node that can intelligently handle all model types. This would be a design that trusted the user to know what they were doing.
Need inference? Load a GDLlama node, load a model, and call an inference method. Need embeddings? Same process. Vision models? Ehh, not implemented, but eventually... a GDLlama node!
Architecture
I knew that the llama_runner was a well-separated piece of code. It handled the core inference logic; awesome. I just needed it to, y'know, work.
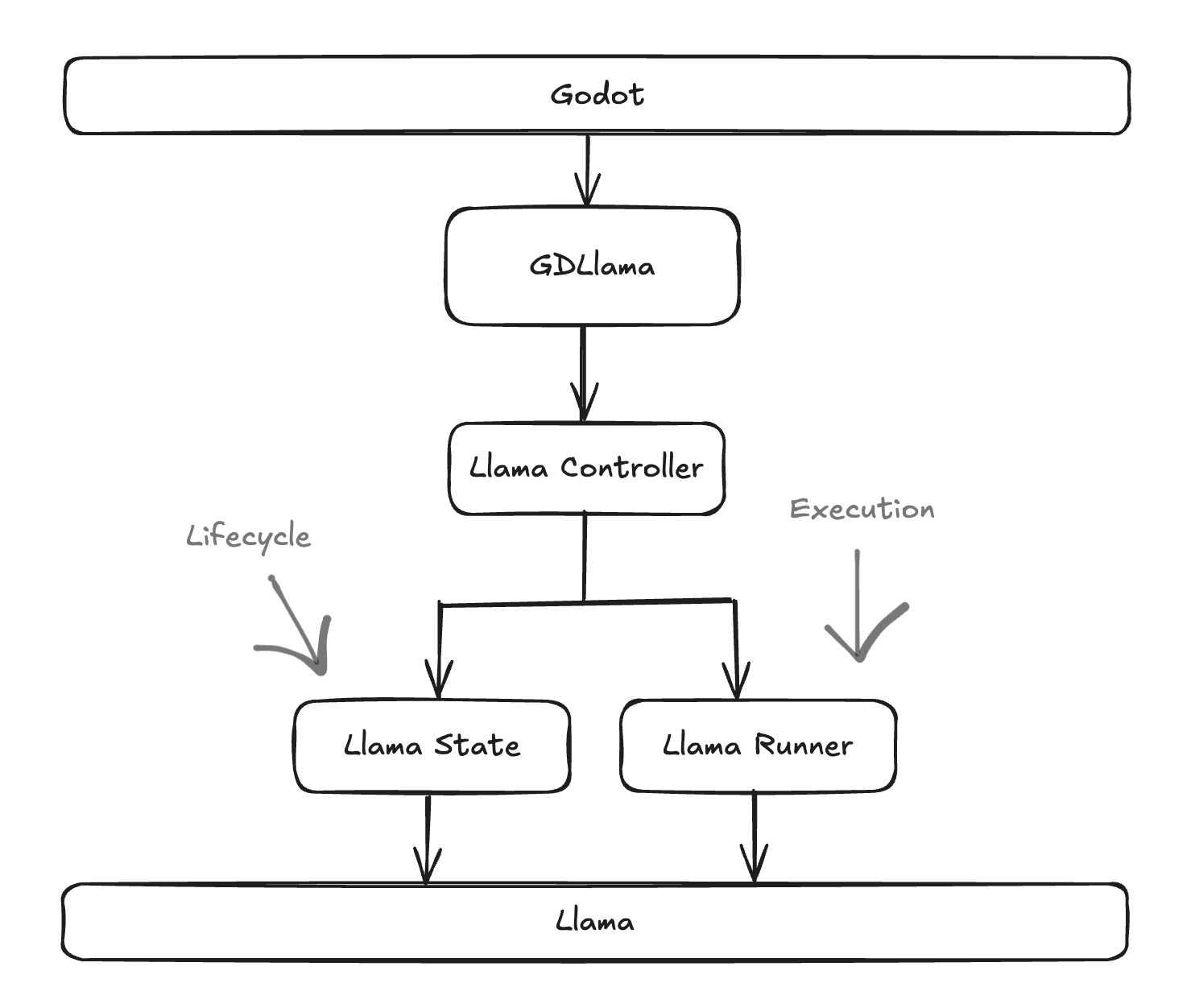
I also realized both llama_runner and gdllama were doing too much between the two of them. gdllama contained access methods, model management, llama/godot communication, and llama_runner had its fingers in generation, state management, and even parts of the model lifecycle. It was a tangled mess that made debugging a nightmare. So, I figured I wanted four main pieces, each with a single responsibility, which conveniently fit into a nice architecture:
gdllama.cpp: Lives in Godot-land. Responsible for exposing access methods to Godot and handling Godot-specific logic and types.llama_controller.cpp: The orchestrator. Manages conversation history, coordinates between the runner and state, and handles the distinction between single-shot and continuous chat generation.llama_state.cpp: The lifecycle manager. Responsible for loading and unloading models, maintaining the llama context, and managing backend initialization.llama_runner.cpp: The execution engine. Handles the low-level prediction and embedding generation loops, including tokenization, sampling, and decoding.
Once I had this structure, I set about creating a structured plan. In GitHub, I created a milestone for the 1.0 release and stocked it full of issues that I wanted to tackle: the aforementioned simplification, bugs with inference, documentation, and so on. There was no real time line, and no real distinction between issues sizes or categories. Just vibes. I started with logging.
Logging was a pain point for me and I didn't know how to debug in C++ at that time. Everything got logged. It was crazy back then. So much logging... but it worked and it helped me find issues very quickly. Some amount of that logging still lives as debug logs, which can be enabled by compiling a debug build! This, I'm sure, will be a huge asset to both myself and future contributors, as well as developers using GDLlama.
The Runner
The heart of the refactor had to revolve around the llama_runner. It did everything and it needed to be re-written completely from scratch. The original runner was a single 1000 line function that handled prompt evaluation, context shifting, different custom modes, and session management all in one loop. Debugging meant scrolling through endless conditionals trying to figure out which state the generator was in. It felt easy to break and hard to verify, especially with while going through llama.cpp updates that changed how generation worked.
I started by writing out, and chatting with Anthropic's Claude, about how I wanted the new runner to work. I wanted clear phases: evaluate, process, generate, done. Each phase would have a clear responsibility and state. I wanted to avoid mixing concerns, and I wanted to make it easy to read and maintain. It took too much trial and error, a learning process, and a lot of iterations but eventually it got there.
The new runner separates the prompt evaluation phase from the generation phase cleanly. During evaluation, we batch process tokens from the prompt using llama_batch_get_one, respecting the n_batch parameter for optimal throughput. Once we're past the prompt, the generation loop becomes straightforward: sample, accept, decode, repeat. The key point is that the new structure is way easier to read, maintain, and debug. Each phase is clear, and the state transitions are explicit.
Embeddings
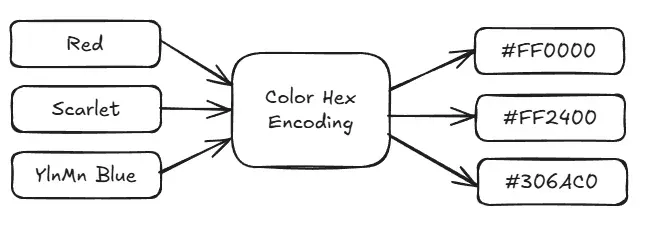
Embedding support was important for me to implement in the initial 1.0 version. For anyone who doesn't know what embeddings are, they are vector representations of text that capture semantic meaning. More simply, consider a color hex code: #306AC0. This code represents a specific shade of blue, which we represent three dimensionally.
- Red: 30,
- Green: 6A,
- Blue: C0
To get a similar color, we can adjust these values slightly. The closer the values are, the more similar the colors will appear.
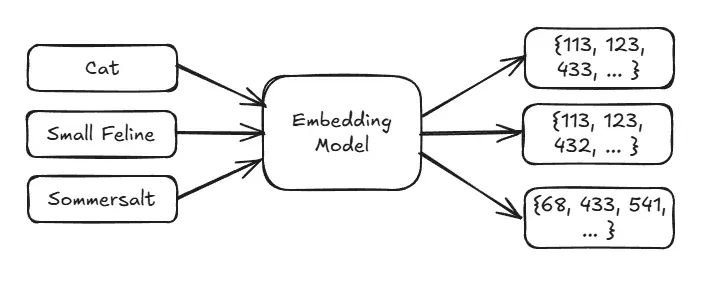
Similarly, embeddings represent text in a high-dimensional space where semantically similar texts are closer together.
Embeddings were implemented, as planned, as part of the GDLlama node. There is no major difference in parameters between inference and embedding calls, so it made sense to consolidate them into a single node. There are separate access methods for generating embeddings versus inference, but under the hood they share the same model loading and management logic. That felt neat!
While developing embedding support, I stumbled upon pooling strategies after a few fruitless evenings of trying to get my embedding tests working. My test model would always return the same semantic distance: 1.0. After some digging, more logging, and a few chats with Claude, I realized the project needed to support multiple pooling strategies.
Different models use different strategies to convert token-level embeddings into a single vector representation for the entire input. Some models use "last-token pooling", where the embedding of the last token is used as the representation. Others use built-in pooling methods like mean pooling or CLS token pooling. The runner detects whether a model uses last-token pooling or built-in pooling (mean, CLS, etc.) and handles each appropriately. This was critical for enabling semantic search and tool-calling features for various models; for testing, I used the Gemma series both for embedding and inference.
Database Concerns
Perhaps controversially, I decided to remove the SQLite database component. While it was a neat thing to have, it introduced a lot of complexity in what was otherwise a fairly straightforward extension. It felt like an extension on top of the extension, and I wanted development and maintenance time focused on the cool and fun functionality. While working on the project, I was thinking of what principles I wanted to follow. One of these was User Agency, styled as "the user should be able to f*ck up." By removing the in-built database, users are free to implement state management solutions in whatever way they see fit without dragging a GDLlama db along; those could be in-memory arrays, JSON, external databases — whatever. The point was, GDLlama didn't need to care. It should work with the user rather than prescribe data management solutions.
Testing and Docs
Testing was done via gtest in debug builds. Nothing fancy, but it gives me confidence when making changes. I set up a continuous integration via GitHub Actions to run the tests whenever master is targeted. In addition, there's a job to pull down and compile against the latest version of llama.cpp weekly, ensuring that I at least know when breaking changes happen upstream.
I spent, what some might call, an inordinate amount of time on documentation. I really hate projects that don't help the user get started, and I really love technical writing — what a delicious combination of traits! So, I wrote a lot of documentation. There are build instructions (important, must have), an API reference (important, must have), a legal guide (sure?), a document on different architecture (okay), a design principles document, and ... I think that's it? I also wrote a few examples to help users get started quickly. I hope it helps! Read the Docs.
Distribution
Out of everything I did, I can't help but laugh about how long I've thought about distribution. I know I wanted to give back to the community, and the project is MIT licensed (and needs to be, given I adopted it from godot-llm). Seriously, after all the hard, technical work in the llama mines, it ends up being distribution that feels the hardest. Talk about a lesson learned! I think what I want is a two-tier system: free access to the source code and build instructions via GitHub, and a paid prebuilt extension via the Godot Marketplace for convenience and a promise of future maintenance. That feels like a fair balance between open source and something I can sustain working on. We'll see how that goes!
The strangest thing about this whole process was the end. I found that when I went to hit that final merge that I didn't want to do it. My mouse hovered over that button and retreated so that I could put one more bit of polish on the code, or so that I could go for a run, or anything but hit that button. It was a strange feeling. I didn't want to be done. I didn't want to put it out there and say, "Here it is, it's ready. Come use it!" I think part of it was that I was nervous about putting my work out there for others to use. What if it had bugs? What if it wasn't as good as I thought it was? Ultimately, I don't think it matters. I did my best. It's out there. Anything that's wrong can be fixed. A good start!
Slop?
I mean, yeah probably. I worry a bit about slop and sloppy content. Mostly, I think that's a taste issue. I built this because I wanted to make games that weren't possible before. My hope is that developers use it to enhance their games in novel and exciting ways, rather than as a crutch to avoid writing engaging content. That's the use case I'm optimizing for: creative people who care about their craft. If you're using GDLlama, make something you'd genuinely want to play. Think about the content you already love and iterate. Be virtuous and make something you love.
Future Plans
Ah, but work is never done. There are a few features I want to add in the future. A request has already come in for adding support for batch processing that I'd like to get to before anything else. LoRA support is another feature that I'd love to add sooner rather than later, since it would open development possibilities that I'd really like to explore myself. I need to hit other integrations (not just Llama ... and that likely means a rename!), allow better context manipulation, and so on, and so on. My continually growing list of features to add is available on the GitHub issues page.
Final Thoughts
It wasn't a perfect project; what is? There are still parts of the code that could be way more modular. The runner could be further split into an "inference" and an "embedding" runner, with shared functions between them. Then, there're three leaky abstractions that I'd like to address:
gdllamatalks tollama.cppwhen setting or getting parameters. This is somewhat okay, and is a simplification. Abstracting this further may add complexity without benefit.llama_controllerdirectly manipulates tokens when managing chat formatting. This should be entirely the domain of the runner!- logging is tightly coupled to Godot. This makes sense, and I'm not sure how to abstract it further without pointlessly adding complexity.
While writing this document, I also found a bug in the current implementation. Exciting! I don't believe infinite generation, so specifying an n_predict of -1 works as intended. Oops! A 1.0.1 will fix that!
But really, I'm incredibly happy with how I wrote this thing. It feels solid, maintainable, and extensible. Not to mention easy to use! I think Godot developers who want to work in this space will find it approachable and fun. And then, when all is said and done, I want to make something. My own game ideas have been on hold while I worked on GDLlama, and I'm eager to get back to them; I'm proud that my work on GDLlama can help me make those ideas a reality. I'm happy to get those ideas out of my notes app! And of course, I hope that others will make great games with GDLlama too.